
Better Refactors Through Deformation Alerting
An application of When & How Will It Break?


You ever wonder what makes a good refactor? Ensuring better problems.
Last week Evan Hu and I were out for a run talking about an in-flight refactor. His company (Shortbread) is an independent, AI scaled, romance comic publisher. Their business depends on delivering hundreds of new pages a week to their customers. Evan built an AI boosted comic creation system that allows their artists to scale far beyond the industry norm. This system has placed inference in the critical path for their artists and any downtime dramatically impacts their ability to deliver and risks leaving their customers unsatisfied.
As the Co-Founder CTO and sole engineer on the team, every time something breaks he’s forced to fix the problem and temporarily abandon growing the business. The routing layer powering the comic creation system had been reliable for the last four months, but during a trip to Spain it snapped as it encountered hidden infra limits.
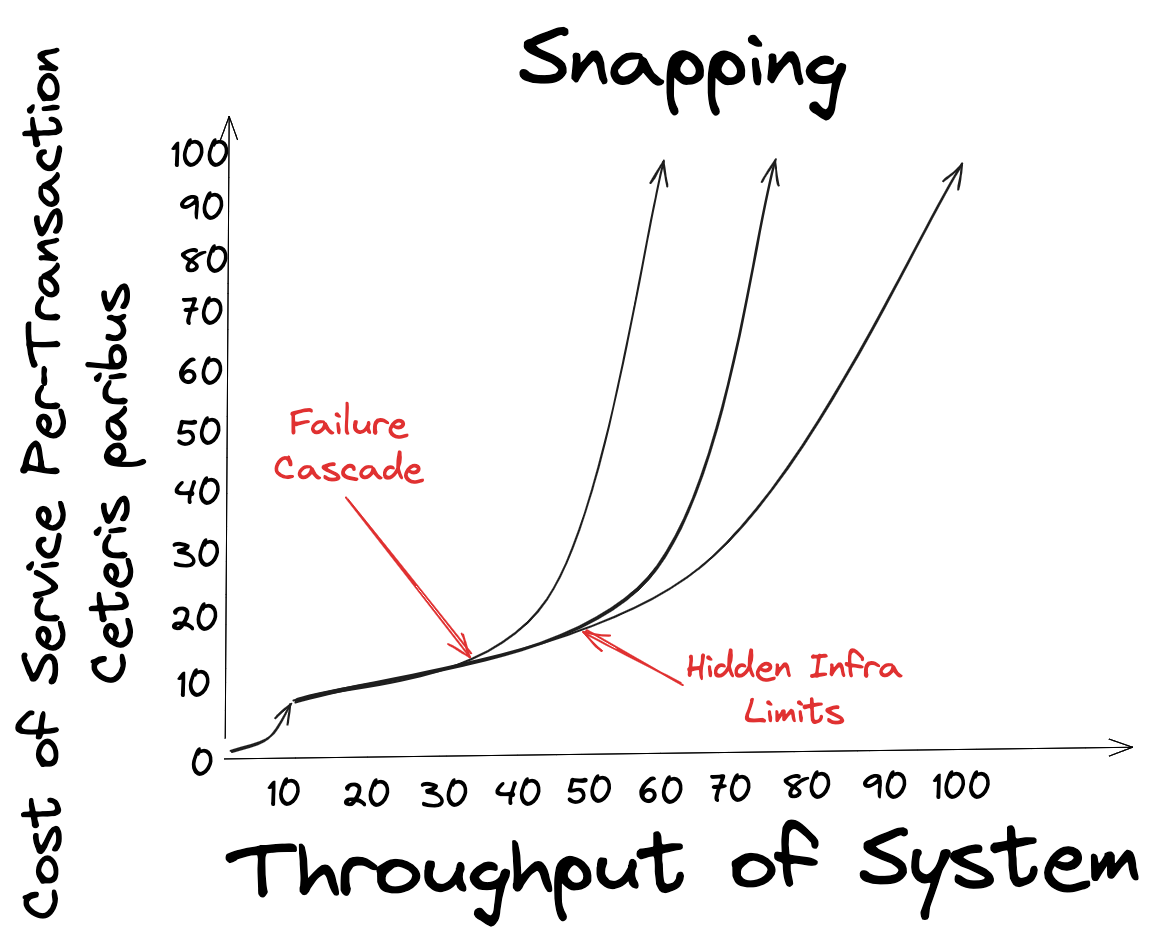
So he embarked on a refactor.
As we talked through our run it became clear that this refactor had the potential to ensure the business scaled through its next growth phase. Unfortunately, as it was currently planned, it would still have the same failure mode: A surprising and frustrating crash at the most inopportune time. So I asked him if he’d think the refactor was worthwhile if it blew up out of the blue four months from now. “No.”.
One of the most difficult things about scaling any business is knowing how to build things such that you can stay proactive and rarely, if ever, are forced into reacting to a critical fire. This is the fabled art of making complex problems disappear. One way to do this is to detect their deformations and respond before they snap. I like to end my runs with coffee, so as we sat down at the cafe I asked if he’d like to explore a better system.
Deformations & Hidden Requirements
With the goal of stability and better failure modes in mind I pushed the conversation through the following questions:
1. What is the amount of downtime per-week of the current system?
Like most early startups, this information wasn’t readily available, so we decided the new system wouldn’t launch without tracking in place, likely using their existing DataDog instance. We’ll talk more about metrics further down.
2. What is an acceptable amount of downtime in this system per-week for the business today?
In every business this is ultimately a function of the business’ sales cycle. Shortbread sells weekly subscriptions paired with a weekly publishing cadence. If they miss a single publishing deadline they fail their customer’s (rightful) expectations. This means the system is unusually sensitive to downtime for a company of this size.
We pegged this number at thirty minutes/week.
3. Assuming the deployment goes well, when should this system be re-examined so that you can stay ahead of any impending failure?
To answer this we explored what prompted Evan to rewrite the system rather than simply kick it until it turned back on. The core driver here is that the bulk of their artists are in China and kicking the system wasn’t a matter of a slack message and a shell script. Any outage in the system meant, at best, lost sleep and sleep deprivation for the rest of the week as he tried to recover. At worst it would mean the artist team lost the day’s work and new comics wouldn’t go out on time, risking customer attrition. A while back I’d heard a great question about working across timezones: Where are you going to put the ocean? It looked like the ocean was threatening to drown Evan.
The realization that the goal wasn’t really to improve system resilience but to preserve Evan’s productivity, revealed a host of hidden requirements. We codified these as:
Self Healing: To minimize interrupting Evan’s sleep and the artist’s work the system would need to be more resilient. It should be able to self-recover from a host of likely issues such as network failures, dead inference workers and stuck jobs.
Incident & Downtime Tracking: Simply tracking downtime wouldn’t be enough to know if the system is starting to [deform or about to snap](https://www.aframeworkforthat.com/p/when-and-how-will-it-break). We also need to track incident rates since each incident risks waking Evan and ruining his week.
Action Driving Alerts: Evan shouldn’t have to wait for his team in China to tell him there’s a problem, the system should be able to alert when the day’s work is at risk or when the system appears to be deforming under load. We decided on setting three distinct types of alerts.
An intervention alert when the system slips above our target incident (2) or downtime (30 minutes) in a rolling seven day window.
A deformation alert when the system is running near (50%) our target incident or downtime per rolling seven days thresholds for longer than fourteen consecutive days.
A snap alert when the system is running 3x above our target incident or downtime in a rolling seven day window.
Each alert type prompts different action. Intervention gets Evan out of bed to quickly paper over the issue to avoid business impact. Deformation requires him to look at the errors and figure out what’s increasing the failure rate and consider planning resolution work. Snap requires him to stop what he’s working on and fix the problem for good. This combination of three distinct thresholds should allow him to stay much more proactive and ultimately more productive.
Here’s what it looks like when you put them all together.



4. How can we ensure the deployment goes well?
To answer this question we explored the existing deployment pipelines he’s got in place and, fortunately, they’re relatively mature. Sadly, given the criticality of the system and the stakes at play, the cold hard truth is that you can’t fully trust your infrastructure. Losing a day of artist time is just too damaging to the business, so you’ll have to personally do post-deployment acceptance testing. We discussed the pros and cons of different deployment times and landed on deploying and testing during US hours then staying on call during Chinese hours. Eventually Evan might be able to move to a more robust set of End to End tests capable of running safely in production to prove this critical system’s function, but we decided that wasn’t worth exploring at this time.
5. Is it worth delaying the release to add all these new features?
This conversation was somewhat more interesting; what is the value of one’s time in this situation? You’ve already sunk three days into this, it’s going to cost another three (between sleep deprivation and so on) to get this thing out the door safely. So it’s a week in. We discussed estimation for the new features and ultimately Evan felt the added cost (a couple more days) would be worth the added visibility and ease of maintenance.
The core of this discussion was the criticality of the system and the cost of even minor outages. If we were talking about something outside the critical path for the business or operated by a team in US timezones this whole refactor might not have been worth doing, let alone the features we’d scoped out over coffee.
I like asking questions, if you’d like to go for a run or have a conversation like this, send me an email at luke + substack at luke mercado dot com.